About Preparing Datasets for Predictive Scenarios
Predictive Scenarios supports acquired datasets and live dataset. However, datasets for predictive scenarios must have a certain structure and must contain some mandatory information depending on the type of predictive scenario you are creating and where you are in the modeling process.
- Acquired: Data is imported (copied) and stored in SAP Analytics Cloud. Acquired dataset have already been prepared on your computer (supported formats are .TXT, .CSV and .XLSX ).
- Live: Data is stored in the source system. It isn't copied to SAP Analytics Cloud, so any changes in the source data are available immediately if no structural changes are brought to the table or SQL view. You can connect to live data and create a live dataset.
Dataset Prerequisites
Depending on the type of predictive model that you are creating, you need to provide some essential information for the input dataset.
Classification and Regression Predictive Model
- Your training dataset contains at least one column for the target variable, and multiple columns for other variables that you think may have an influence on the target variable. These variables are called Influencers.
- The datasets used to train and apply a predictive model must come from the
same type of data source (acquired or live). You can't apply a predictive
model on a live dataset if it was trained with an acquired dataset, nor can
you apply a predictive model on an acquired dataset if it was trained using
a live one. However, you can have several predictive models trained and
applied with live and acquired datasets in the same predictive
scenario.NoteWhile using live datasets, both live datasets (training and apply datasets) must come from the same SAP HANA system: you cannot train a predictive model with a live dataset with data from SAP HANA system 1 and then apply this predictive model on a live dataset with data coming from SAP HANA system 2.
Times Series Forecasting Predictive Model
- Your training dataset contains a column for the signal variable. This contains the value that you want to forecast. The signal variable has to be continuous, with no missing values.
- Your dataset contains a column for the date variable. NoteThe date formats must be:
- YYYY-MM-DD
- YYYY/MM/DD
- YYYY/MM-DD
- YYYY-MM/DD
- YYYYMMDD
- YYYY-MM-DD hh:mm:ss
where YYYY stands for the year, MM stands for the month, DD stands for the day of the month, hh stands for hour, mm stands for minutes, and ss stands for seconds.ExampleJanuary 25, 2018 will take one of the following supported formats:- 2018-01-25
- 2018/01/25
- 2018/01-25
- 2018-01/25
- 20180125
-
Forecast accuracy can be improved when the training dataset includes influencers. These are other variables that you think may have an influence on the signal variable. While values would normally be available for these over the observation period, you must ensure that values for influencers are also provided for the period you want to forecast. If values for influencers to cover the forecasted periods are not available, the predictive model won’t be successful, as you need observations to cover all of the requested forecast dates.
For example, if you want to forecast chocolate sales for the year, you could add the specific dates of festive occasions to your dataset, for example, Easter, Christmas, Mother’s Day, or Valentine's day.NoteThe predictive forecasts will be influenced by the quality of the data you provided: both the historical data but also the future values for the influencers can impact your predictive model's accuracy. In some cases, it can be difficult to provide data with high quality for future values. For example: Future values for weather information can only be forecasts.
Dataset Structure
To be used in SAP Analytics Cloud, your dataset must contain columns
(corresponding to the variables) and rows (corresponding to the observations):
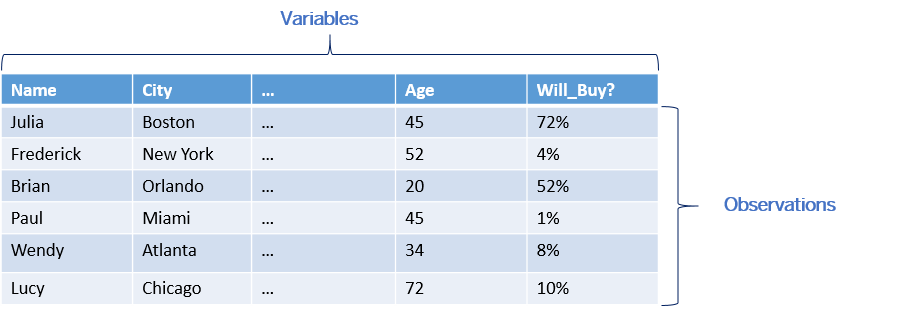
When the goal is to create a classification or regression predictive scenario, the corresponding training dataset must contain at least one column for the target variable and multiple columns for influencer variables.
-
A column with the date variable (one date per period of time). The date formats must be one amongst:
- YYYY-MM-DD
- YYYY/MM/DD
- YYYY/MM-DD
- YYYY-MM/DD
- YYYYMMDD
- YYYY-MM-DD hh:mm:ss
where YYYY stands for the year, MM stands for the month, DD stands for the day of the month, hh stands for the hour, mm stands for the minutes and ss stands for the seconds.ExampleJanuary 25, 2018 will take one of the following supported formats:- 2018-01-25
- 2018/01/25
- 2018/01-25
- 2018-01/25
- 20180125
-
A column with the value that you want to forecast, being the signal variable.
- While this is not mandatory, we highly recommend also including influencer variables as part of the training dataset for the past dates and for the forecasted period, in order to improve the forecast accuracy.
-
The consumption (signal variable) for the past date.
- The date (date variable), including one date per month over several years.
- The consumption by sector (segmented by).
- Eventually influencer variables (for example, various calendar events) that happen in the past and in the next 24 months.
To summarize your dataset must contain the right data in the right format, depending on the type of predictive scenario.
Creating an Acquired Dataset
You create an acquired dataset following these step from  Datasets start page, select
Datasets start page, select  From a CSV or Excel File
From a CSV or Excel File .
.
Creating a Live Dataset
- Ensure that a connection has been established between your SAP HANA on-premise system and SAP Analytics Cloud. For more information, see Live Data Connection Overview Diagram.
- Ensure that you have one of the following security roles: Predictive Admin,BI Admin, or Admin.
- From the Datasets
start page, select Create
 Dataset. And select Data from a data
source.
Dataset. And select Data from a data
source. - From the Connect to Live Data area, select your
existing SAP HANA Live Data Repository and fulfill the steps
to complete connection:
Information requested What does it mean 1- Select a Data Repository Select the Data Repository, which has been set up to create your live datasets. 2- Select a table The existing schemas available for this Data repository are displayed. Select the one that points to the actual data stored in your SAP HANA on premise system. - Give a name to your dataset in SAP Analytics Cloud and save it.
-
Retrain your predictive model if you want to get it updated.NoteThis step is recommended for Time series predictive models.
- Re-apply the updated predictive model to get the output SAP
HANA table updated. The updated predictions will be
right-away visible into your stories.NoteWhen applying classification and regression predictive models, make sure to select the exact same list of predictive outputs so that the existing output table can be updated in SAP HANA.
Differences Between Acquired and Live Datasets
In SAP Analytics Cloud you can use one of the following types of input datasets:
- Acquired: Data is imported (copied) and stored in SAP Analytics Cloud. Changes made to the data in the source system don't affect the imported data.
- Live: Data is stored in the source system. It isn't copied to SAP Analytics Cloud, so any changes in the source data are available immediately if no structural changes are brought to the table or SQL view.
When you select an input dataset to create a predictive model, you won't see any distinction
between acquired and live datasets, although it is a good practice for the administrator
creating the connection to a dataset to include "live" in the dataset name, or its
description. You can also see live datasets in the list of objects available to you on
the page Browse Files <User> as they include (Live) in the file type.
There are some differences between the two types of input datasets that concern mainly the display of results in the predictive model debrief, and how some types of data are handled, when training or applying a predictive model. These differences will be resolved over time, as predictive models are improved with each release of SAP Analytics Cloud, but for the immediate future, please take into account the following differences that can be observed when using either an acquired or live input dataset:
| Element | Acquired dataset | Live dataset |
|---|---|---|
| Support of data type conversion In the column Storage under Edit Variable Metadata, you can specify the data type for each variable. |
Available If necessary, the physical data type, for example, a string, is automatically converted to the data type specified by the user, for example, a number. |
Not available Note Training a predictive model won't complete if
a user specified data type doesn’t match the physical data
type. |
The type of dataset you have used to train and apply your predictive model will impact the way you will consume the generated predictions in SAP Analytics Cloud. For more information, see Using the Generated Dataset in SAP Analytics Cloud.
Datasets - Examples
Your dataset must have a specific structure so that it can be relevant for Smart Predict.
How a classification or regression predictive scenario training dataset must be structured?
Example of a training dataset used for a classification predictive scenario
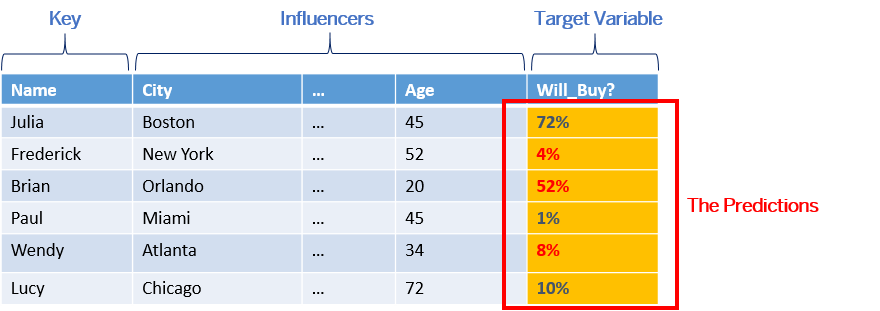
In the example below, you want to predict if a customer will buy a product or not. You have prepared a training dataset containing the historical data on customers that have previously bought a similar product. In this dataset, the values of the target variable ("did the customer buy the product?") are known .
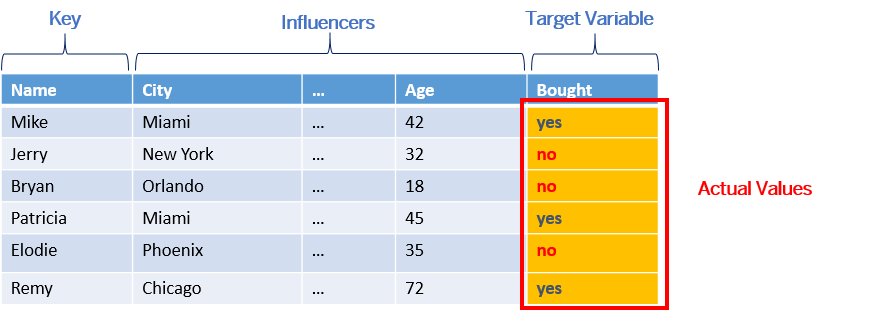
Once you have created your predictive model, you apply it to an application dataset. This dataset contains the same information about the customers you want to target with the new product. The target variable column ("Will_Buy?") is empty or even doesn't exist because this is what you are expecting to predict:
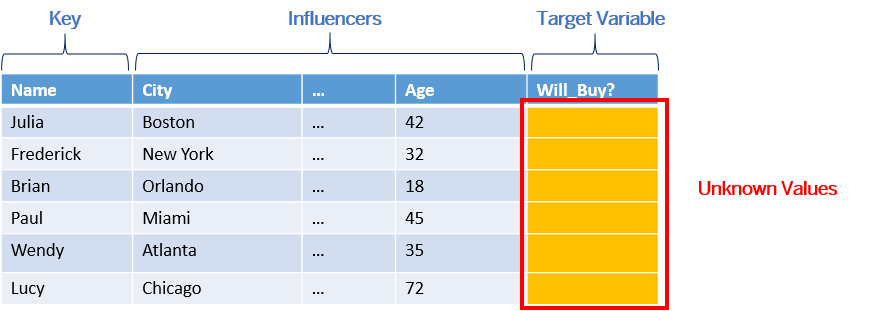
Smart Predict will use the predictive model to calculate the probability that each customer will buy the product. The column "Will_Buy?" is now filled in the generated dataset:
Example of a training dataset used for a regression predictive scenario
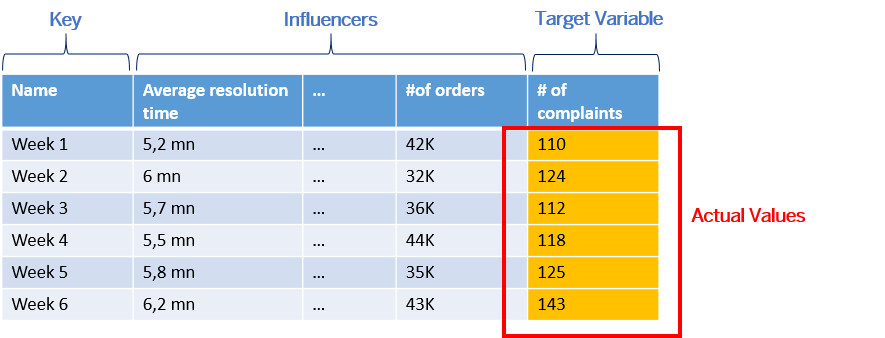
In the example below, you want to predict the number of complaints that your customer support will receive this week. You have prepared a training dataset containing historical values for several previous weeks. In this dataset, the values of your target variable ("how many complaints per week") are known:
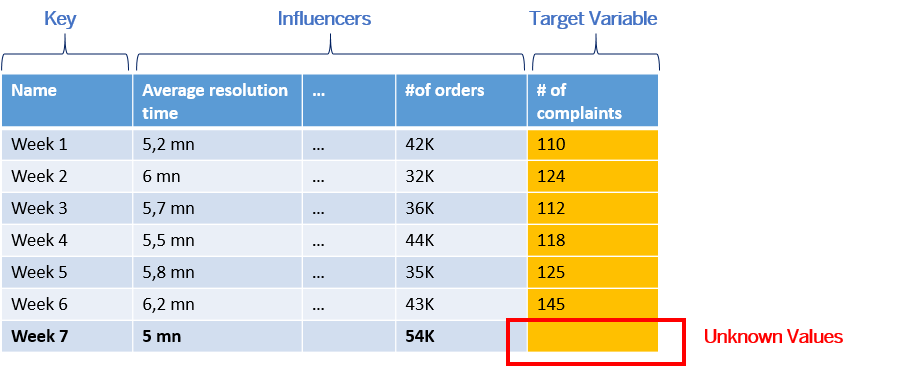
You apply the regression predictive model to a new dataset which contains the same influencers. The values of the target variable for this week ("number of complaints this week") are unknown.
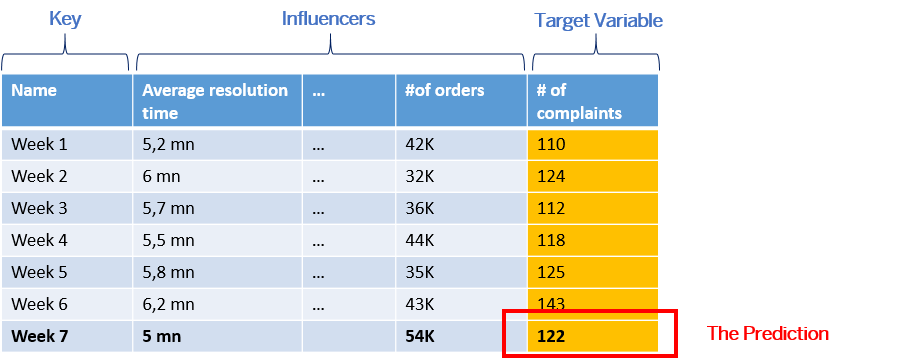
The predictive model makes a prediction of the number of complaints that can be expected this week.
How a time series predictive scenario training dataset must be structured?
Example of a dataset used for a time series predictive scenario (Non-segmented):
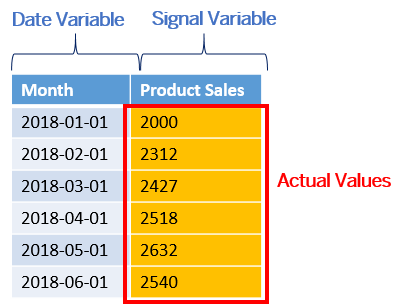
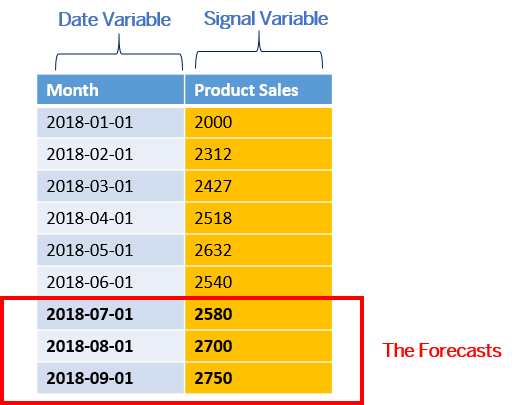
The training and the application are done at the same time: it consists of generating N forecasts in the future. In this example, we want to generate product sales forecasts for the next 3 months.
The generated dataset will look like the one displayed below:
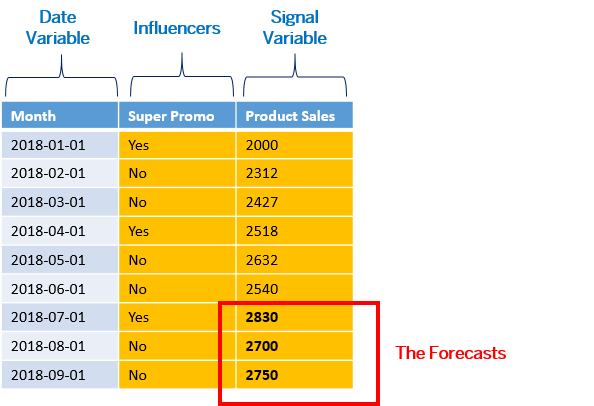
You can include influencers in your data model to refine the forecasts. In fact, this is highly recommended for improving forecast accuracy. The values for these influencers are filled in for the next 3 months as well:
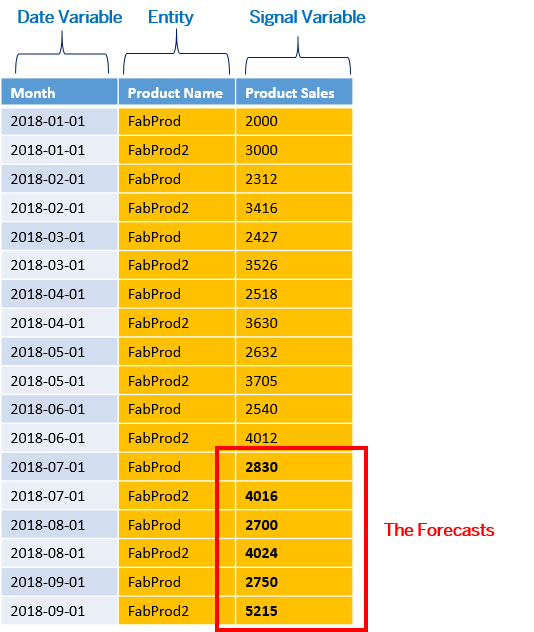
Example of a training dataset used for a time series predictive scenario with entities:
You can also forecast product sales for multiple products. You will need to add the product-related information to the dataset. In Smart Predict, you will specify that the variable "Product Name" will be used to split your predictive model into distinct entities:
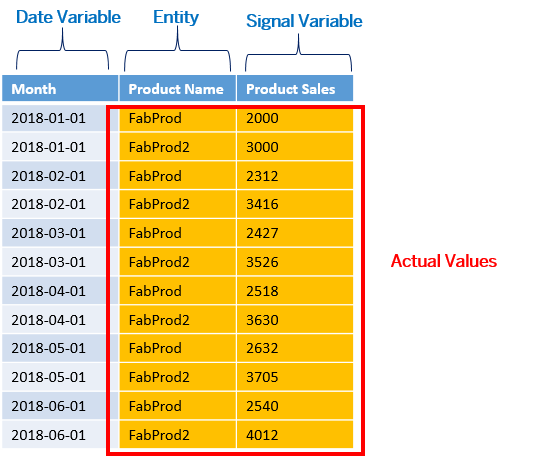
In the generated dataset, the observations are divided into "Product Name" and you will get forecasts per product:
Of course, you can combine entities and influencers. In fact, this is recommended if you want to increase the accuracy of your time series models.