Import and Prepare Fact Data for a Model with Measures
Once your new model is created, you might want to import fact data to your model.
In this section, we describe each step required to import data acquired from an external data source into the fact table of your new model type. There are four main steps in the import process: creating an import job, preparing the data, mapping the data, running the import. You can also schedule import jobs to import data on a one time or recurring basis. Depending on whether you're working with an SAP data center (Neo) or non-SAP data center (Cloud Foundry), the user interface and procedure can slightly differ. When that is the case, it will be explicitly mentioned in the sections below.
Creating an Import Job
Context
- SAP BPC
- SAP Concur
- SAP ERP
- SAP Fieldglass
- Workforce Analytics
- Dow Jones
Also, for the Salesforce data source, importing data into an existing model isn't supported.
Procedure
-
Select
 Import Data from
Import Data from  File
File or Import Data from Data Source depending where your data is stored.
or Import Data from Data Source depending where your data is stored.
-
Select the data you want to import.
The import job is added to the Draft Sources or Import Jobs list, depending on whether you're working with a classic account model or a model with measures (i.e, the new model type). At this moment, you can save and exit the process and come back later by clicking
 . The uploaded draft data
expires 7 days after the upload.NoteThe draft source is visible to anyone with imports rights to the model.
. The uploaded draft data
expires 7 days after the upload.NoteThe draft source is visible to anyone with imports rights to the model.
Results
Preparing the Data
The data preparation step is where you can you can resolve data quality issues before the mapping step, but also wrangle data and make edits such as renaming columns, create transformations, etc…
First, make sure to resolve data quality issues if there are any. After the initial data import, the Details panel gives you a summary of the characteristics of the model with general information about the imported data, including any data quality issues.
For tenants based on an SAP Data Center, issues can be listed and described under the Model Requirements section if they are related to the model itself, or under the Data Quality section when you click a particular dimension.
For tenants based on a non-SAP Data Center, the Details panel list all the dimensions and measures of the model. You can click the icon to access more information. If ever the application has detected issues with a dimension, the exact number of issues with that particular dimension is indicated right next to its name, and clicking that number takes you straight to the Validation tab, where you can see a description of the issue.
Select a message to see the options available to resolve any identified quality issue. Use the context-sensitive editing features and the transform bar to edit data in a cell, column, or card. When selecting a column, a cell, or content in a cell, a menu will appear with options for performing transforms. This menu is two-fold:
- Choose the
Quick Actions option to perform actions
such as duplicate column, trim whitespace, hide columns, or
delete columns or rows. The table below lists all the available
actions.
- Select the
 (Smart Transformations) icon to list
suggested transformations to apply to the column, such as
replacing the value in a cell with a suggested value. You can
also select Create a Transform and choose
from the options listed under the transformation bar displayed
above the columns. The transformation bar is used to edit and
create transforms.
(Smart Transformations) icon to list
suggested transformations to apply to the column, such as
replacing the value in a cell with a suggested value. You can
also select Create a Transform and choose
from the options listed under the transformation bar displayed
above the columns. The transformation bar is used to edit and
create transforms.
As you hover over a suggested transformation, the anticipated results are previewed in the grid. To apply the transformation, simply select the transform. You can manually enter your own transformation in the transformation bar; as the transform is built, a preview is provided in the affected column, cell, or content within the cell. The table below summarizes the available transformations you can apply to selected columns, cells, or content within cells.
| Transformation | Description | Transform Bar Format |
|---|---|---|
| Delete Rows | Delete rows in the data, either by selecting individual members, or by specifying a range (not possible for text columns; only numerical and Date columns). | Provided only as a quick action |
| Trim Whitespace | Remove spaces, including non-printing characters, from the start and end of strings. | Provided only as a quick action |
| Duplicate Column | Create a copy of an existing column. | Provided only as a quick action |
| Delete Column | Delete a column. Use the Shift key to select and then delete multiple columns. | Provided only as a quick action |
| Remove duplicate rows | Remove duplicate rows when creating or adding data to a model. | Provided only as a task bar icon |
| Concatenate | Combine two or more columns into one. An optional value can be entered to separate the column values. | Concatenate [<Column1>], [<Column2>]… using "value" |
| Split | Split a text column on a chosen delimiter, starting from left to right. The number of splits can be chosen by the user. | Split [<Column>] on "delimiter" repeat "#" |
| Extract | Use this transform to extract a block of text specified as numbers, words, or targeted values within a column to a new column. | Extract [<what to extract]>]
[<where to extract>] [<which
occurrence>] [""] from [<column
name>] [<include value option>
]. Options for what to extract:
Options for where to extract relative to the target
value:
Options for specifying occurrence:
To extract the first number from all column cells, you would specify the following: Extract before first "" from [<column name>].To extract all text between parenthesis in column cells, you would specify: Extract everything between "(" and ")" from [<column name>]. |
| Change | Change a column to uppercase, lowercase, or title case. | Change [<Column>] to (<UPPERCASE>/<lowercase>/<TitleCase>) |
| Replace | Replaces either an entire cell or content that could be
found in multiple different cells. Note You can optionally
select  where to add a <where> clause
to the transform bar. You need to specify an associated
column and value when using a <where>
clause to limit the replace action in a given
column. where to add a <where> clause
to the transform bar. You need to specify an associated
column and value when using a <where>
clause to limit the replace action in a given
column. |
Replace (<cell/content>) in
[<Column>] matching
"value" with
"value" With a <where> clause: Replace (<cell/content>) in [<Column>] matching "value" with "value" where[<Column>]is "value" |
A history of all transforms you implement is displayed in Transform Log. There are two levels of transformation logs recorded: transforms on the entire dataset, and transformations on the currently selected column. Hover over a specific transform in the Transform Log to highlight the impacted column. You can roll back the change by either deleting the entries in the history or using the (Undo/Redo) buttons on the toolbar. You can remove transforms in the Transform Log panel out of sequential order provided that there are no dependencies.
- Numerical histograms are vertical, and represent the range of values along the x-axis. Hover over any bar to show the count, minimum, and maximum values for the data in the bar. The number of bars can also be adjusted by using the slider above the histogram. Checking the Show Outliers (SAP Data Center) or Include Outliers (Non-SAP Data Center) option includes or removes outliers from the histogram. Below the histogram, a box and whisker plot help you visualize the histogram's distribution of values.
- Text histograms are horizontal, and the values are clustered by count or
percent. The number of clusters can be adjusted by dragging the slider shown
above the histogram. When a cluster contains more than one value, the displayed
count is the average count for the cluster. The count is prefaced by a tilde
symbol (~) if there are multiple different occurrences. Expand the cluster for a
more detailed view of the values in the cluster along with individual counts.
Use the search tool to look up specific column values, and press Enter
to initiate the search. When you select a value in the histogram, the
corresponding column is sorted and the value is highlighted in the
grid.NoteThe displayed histogram is determined by the data type of the column. A column with numbers could still be considered as text if the data type is set to text.
Selecting Dimension Types
When you create an import job, the application automatically qualifies the data. Typically, columns containing text are identified as dimensions, and columns containing numeric data are identified as measures. You can still change the data qualification and change it to another type if needed. For example, you can change a Date dimension to an Organization dimension.
If you’re unsure about dimension types, make sure to check out Learn About Dimensions and Measures.
After you've selected your dimensions make sure to follow the best practices described in the sections below.
Maximum Number of Dimension Members
To maintain optimal performance, the application sets a limit to the number of unique members per dimension when importing data to a new model. For more information, check out System Requirements and Technical Prerequisites.
- In the data integration view, these dimensions cannot have any dimension attributes added to them, such as description or property.
- Once the dimensions are imported into the Modeler, they have only one ID column, and are read-only.
- The dimensions can't be used as exception aggregation dimensions or required dimensions.
- The dimensions can't be referenced in formulas.
Calculated Columns
While you're preparing data in the data integration view, you can create a calculated column based on input from another column and the application of a formula expression.
Click from the menu toolbar, and use the Create Calculated Column interactive dialog to build up your calculated column. Add a name, and build the formula for your column in the Edit Formula space. You can either select an entry from Formula Functions as a starting point or type “[" to view all the available columns. Press Ctrl + Space or Cmd + Space to view all the available functions and columns.
Click Preview to view a 10 line sample of the results of the formula. Click OK to add the calculated column to the model. If necessary, you can go back and edit the calculated column’s formula by clicking Edit Formula in the Designer panel.
For a listing of supported functions, see Supported Functions for Calculated Columns.
Dimension Attributes
Dimension attributes are information that is not suitable to be standalone dimensions. You can use them to create charts, filters, calculations, input controls, linked analyses, and tables (with “import data” models only). For example, if you have a Customers column, and a Phone Numbers column, you could set Phone Numbers to be an attribute of the Customers dimension.
- Description: The column can be used for
descriptive labels of the dimension members when the member IDs (the
unique identifiers for the dimension members) are technical and not
easily understandable.
For example, if your imported data contains a pair of related columns Product_Description and Product_ID with data descriptions and data identifiers, you can set Product_Description to be the Description attribute for the Product_ID dimension. Note that the Product_ID column would then need to contain unique identifiers for the dimension members.
- Property: The column represents information that is related to the dimension; for example, phone numbers.
- Parent-Child Hierarchy (Parent): The column is
the parent of the parent/child hierarchy pair.
For example, if your imported data contains the two columns Country and City, you can set the Country column to be the parent of the Country-City hierarchy.
The hierarchy column is a free-format text attribute where you can enter the ID value of the parent member. By maintaining parent-child relationships in this way, you can build up a data hierarchy that is used when viewing the data to accumulate high-level values that can be analyzed at lower levels of detail.
You can also create level-based hierarchies when your data is organized into levels, such as Product Category, Product Group, and Product. When the data is displayed in a story, hierarchies can be expanded or collapsed. In the toolbar, select
 (Level Based Hierarchy). For more
information about hierarchies, see Learn About Hierarchies.
(Level Based Hierarchy). For more
information about hierarchies, see Learn About Hierarchies. - Currency: If you set a column to be an Organization dimension, the Currency attribute is available. The Organization dimension offers an organizational analysis of the account data, based, for example, on geographic entities. You can add the Currency attribute to provide currency information for the geographic entities.
Data Quality Considerations
- In account dimensions, dimension member IDs cannot contain the following characters: , ; : ' [ ] =.
- Numeric data cells in measures cannot contain non-numeric characters, and scientific notation is not supported.
- When importing data to an existing model, cells in a column that is mapped to an existing dimension must match the existing dimension members. Unmatched values will result in those rows being omitted from the model.
- For stories, if any member IDs are empty, you can type values in those cells, or select Delete empty rows in the Details panel to remove those rows.
- When creating a new model, if member IDs are empty, they are automatically filled with the
“#” value if you select the Fill applicable empty ID cells with
the "#" value option. Otherwise, those rows are omitted from
the model.NoteThis option is only available on for tenants based on an SAP Data Center (Neo).
- In dimensions and properties, a single member ID cannot correspond to different
Descriptions in multiple rows (but a single Description can correspond to
multiple member IDs).
For example, if member IDs are employee numbers, and Descriptions are employee names, you can have more than one employee with the same name, but cannot have more than one employee with the same member ID.
- In a Date dimension column, cell values must match the format specified in the Details
panel.
The following date formats are supported: dd-mm-yy, dd.mm.yy, dd/mm/yy, dd-mm-yyyy, dd.mm.yyyy, dd/mm/yyyy, dd-mmm-yyyy, dd-mmmm-yyyy, mm-dd-yy, mm.dd.yy, mm/dd/yy, mm-dd-yyyy, mm.dd.yyyy, mm/dd/yyyy, mm.yyyy, mmm yyyy, yy-mm-dd, yy.mm.dd, yy/mm/dd, yyyq, yyyy, yyyymm, yyyy-mm, yyyy.mm, yyyy/mm, yyyymmdd, yyyy-mm-dd, yyyy-mm/dd, yyyy.mm.dd, yyyy/mm-dd, yyyy/mm/dd, yyyy.mmm, yyyyqq.
Examples:- mmm: JAN/Jan/jan
- mmmm: JANUARY/January/january
- q: 1/2/3/4
- qq: 01/02/03/04
- Latitude and longitude columns, from which location dimensions are created, must contain values within the valid latitude and longitude ranges.
- For planning-enabled models, in a hierarchy measure, non-leaf-node members are not
allowed.NoteFor analytic (non-planning-enabled) models only, non-leaf node members are allowed, but be aware of the effects of this behavior. For example: in an organizational chart that includes employee salaries, the manager has her individual salary, and her staff members have their own salaries as well. In a visualization, do you expect the manager’s data point to reflect her individual salary, or the sum of her staff members' salaries?
Mapping the Data (Non-SAP Data Center Tenants)
Now that the data is prepared, you can start the mapping process. The application automatically pre-maps some parts of the data, and you can map the remaining data manually.
Context
- All dimensions are mapped.
- If the Version is mapped to a column, then the Category is also mapped to a column.
- There is only one Actuals version in the model.
- The Actuals category is mapped to public.Actuals for planning models.
- There is at least one measure mapped for the model.
- If there are multiple hierarchies in the dimension, and some dimension
members don’t belong to all the hierarchies, we recommend carrying out
multiple data imports, one for each hierarchy.
When the source column is mapped to a hierarchy of the target dimension, an empty cell in the source column means that after the import, the member will become the top node of the hierarchy, displayed as <root> in the dimension.
That empty cell during the data import does not mean that the member is excluded from the hierarchy. To make sure that this dimension member does not belong to a hierarchy after the import, you can either filter out the value using the delete row function during the data preparation step in the import mapping screen first, or do not map a column to the target hierarchy.
- We do not recommend adding the <root> or Not In Hierarchy members in the data source itself when importing data to a hierarchy, as these are interpreted as regular strings by the application and might cause unexpected issues in the dimension.
Procedure
- Optional:
If needed, you can also set default values to dimensions. In the
Unmapped column, click in the
Source section next to an unmapped dimension, and
select Set default value to "#" or Set default
value....
-
Map the version:
- If you have a single version, you can select a default value and map all rows to that
version. Click in the Source section
next to the version and click Set default value, and
select a version. Each version is described with its version
category.
- Alternatively, if the data you're importing has a version, you now have to handle
multiple versions in the dataset. Map the version you have just imported to
the version dimension in the Target column. This
allows you to assign rows to multiple versions.NoteIf you have multiple versions, it is required to map the Category attribute in the next step. If you don't have one, go back to the data preparation step and create one.
- If you have a single version, you can select a default value and map all rows to that
version. Click
Results
Mapping the Data (SAP Data Center Tenants)
Now that the data is prepared, you can start the mapping process. The application automatically pre-maps some parts of the data, and you can map the remaining data manually.
Context
- All dimensions are mapped.
- If the Version is mapped to a column, then the Category is also mapped to a column.
- There is only one Actuals version in the model.
- The Actuals category is mapped to public.Actuals for planning models.
- All measures are mapped.
- If there are multiple hierarchies in the dimension, and some dimension members don’t belong
to all the hierarchies, we recommend carrying out multiple data imports, one
for each hierarchy.
When the source column is mapped to a hierarchy of the target dimension, an empty cell in the source column means that after the import, the member will become the top node of the hierarchy, displayed as <root> in the dimension.
That empty cell during the data import does not mean that the member is excluded from the hierarchy. To make sure that this dimension member does not belong to a hierarchy after the import, you can either filter out the value using the delete row function during the data preparation step in the import mapping screen first, or do not map a column to the target hierarchy.
- We do not recommend adding the <root> or Not In Hierarchy members in the data source itself when importing data to a hierarchy, as these are interpreted as regular strings by the application and might cause unexpected issues in the dimension.
Procedure
-
Switch to the
 Card View and determine what remains to be mapped. Cards
display as either mapped or unmapped entities. A card represents mapped data if
it is shaded solid and has defined borders. Cards that must be mapped appear
transparent and borderless.
Card View and determine what remains to be mapped. Cards
display as either mapped or unmapped entities. A card represents mapped data if
it is shaded solid and has defined borders. Cards that must be mapped appear
transparent and borderless.
Dimensions with attributes appear stacked and can be expanded. Mapping attributes is optional.
-
Once you have mapped all cards, check for mapping issues. If there are any, fix
them before moving to the next step.
A red dot in the top right corner of the card indicates there are mapping errors that need to be addressed. A blue dot indicates that new values have been added from the import to the existing data.
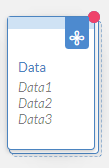
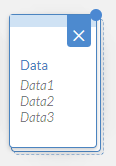
Results
Reviewing and Running the Import
Once the mapping is complete, you're ready to review the import options and method before running the import job.
Context
Procedure
Changing the Data Source of an Import Job (Non-SAP Data Center Tenants Only)
In the Data Management space, you can edit the data source and the query definition of an import job for models with measures if needed.
Context
This flexibility is helpful to adapt to possible changes on the external data source, or simply to repurpose an existing job for another data source without redoing all the upfront configuration.
If the target model itself has changes, changing the data source of an import job is also beneficial because it allows you to run the data transformation steps and redo the data mapping to the target model.
When doing so, you replace the existing data source with a new one and create a whole new query, and run data preparations operations. After the change, you can also review the import settings if needed.
- Columns from the new data source with the same name as column from the original data source are mapped automatically.
- Any pre-existing mapping attached to a column from an original data source is automatically removed if there isn’t a match column in the new data source.
If needed, you can edit the import settings at any time to review the mapping and map columns that haven’t been mapped automatically.
Procedure
- In the Modeler, go to the Data Management space.
- In the Import / Export Jobs tab, select an import job and click the three dots menu.
-
Select Edit Replace Data Source.
- Select a data source.
- Select a connection.
- Add a name to the query, and select the objects you would like to include in the query.
- Build a new query using the objects you have selected previously.
- Click Run Query.
Scheduling an Import Job
Schedule a data import job if you want to refresh data against the original data source. You can import data from multiple queries and data sources into a model, and each of these imports can be separately scheduled.
Context
Procedure
-
Select one or multiple import jobs you want to schedule.
If you select multiple jobs, you can order them, set a group name for the job, and select one of the group processing option:
- Stop if any query fails: If any of the import jobs fails, the group processing stops. You can then cancel the remaining jobs, or try to fix the cause of the failure, and later resume execution of the grouping from the same point where execution stopped.
- Skip any failed query: If any of the import jobs fails, the remaining jobs are still processed.
NoteA grouping can include jobs from public dimensions as well as the model. Running the grouping refreshes the public dimensions and model together. You can ungroup your import at anytime clicking. -
Define the frequency for the scheduling:
- None: Select this option when you want to update the data manually.
- Once: The import is performed only once, at a preselected time.
- Recurring: The import is executed according to a recurrence pattern.
You can update the schedule at anytime clicking.